Il progetto di ricerca SS-RR (Sviluppo di un Sistema per la Rilevazione della Risonanza) si pone l’obiettivo di sviluppare delle metodologie che, supportate da tecnologie esistenti, possano dar vita a servizi innovativi. In particolare lo scenario in cui ci si muove è quello in cui vi è interesse a rilevare i livelli di armonia relativi ad uno o più individui in relazione ad una serie di eventi e stimoli esterni. Ci si riferisce, ad esempio, alla misurazione del gradiente di soddisfazione di un interlocutore, al gradiente di felicità di un soggetto intervistato, al gradiente di interesse di uno studente nel corso di una lezione, etc. Da questo punto di vista, l’innovazione e l’utilità portati dal programma potranno tradursi nella moderna volontà di conoscere la sintonia esistente tra le persone che interagiscono, nella misurazione della accresciuta conoscenza, preparazione o interesse maturati a valle di un confronto, di un dialogo, di una lezione, di un’indagine, di un’esperienza di gruppo. Il Tema del Programma ovviamente riguarda il Settore dell’ICT – Informatica (architettura e sistemi di elaborazione) e prevede lo sviluppo di applicazioni software in grado di girare su opportuni dispositivi hardware. Attualmente esistono dispositivi con alcune di tali funzionalità, si pensi per esempio alle cosiddette macchine della verità, ma essi risultano essere di fatto inutilizzabili in contesti reali e difficilmente accettabili dagli utenti a causa della loro invasività. Questo progetto ha l’obiettivo di utilizzare le tecnologie attualmente disponibili sul mercato per creare dei servizi a valore aggiunto. In particolare utilizzando dispositivi quali smart-phone, iPhone, palmari, portatili di ultima generazione è possibile pensare di utilizzare dei software associati ad opportuna sensoristica in grado di acquisire informazioni sullo stato emotivo di chi si sta monitorando. I dati a cui si fa riferimento sono quelli propri del corpo umano sottoposto a particolari sollecitazioni fisico-emotive. Dall’incrocio di questi dati sarà possibile, attraverso sofisticati modelli propri della psicologia, ricostruire il gradiente di soddisfazione di un interlocutore, il gradiente di felicità di un soggetto intervistato, il gradiente di interesse di uno studente nel corso di una lezione, etc. Come precedentemente argomentato, quindi, non sarà necessario utilizzare sofisticate apparecchiature invasive, ma unicamente sfruttare le possibilità fornite dai moderni dispositivi, l’introduzione di modelli derivanti dalla psicologia e in grado di legare parametri fisici-emozionali a stati della persona e l’utilizzo di software appositamente progettati ed implementati in grado di collezionare, attraverso l’utilizzo di semplici dispositivi non invasivi, simili all’iPod per tipologia e dimensione, i dati.
Attraverso lo sviluppo della presente iniziativa si è progettato e implementato un Sistema per la rilevazione della Risonanza nei processi di profilazione e selezione del personale, tra due o più soggetti, al fine di misurare il gradiente di risonanza rilevabile quale parametro di effettiva sinergia esistente. L’obiettivo è stato dunque quello di realizzare un software che possa essere installato a bordo di strumentazioni da utilizzarsi durante la fase di un colloqui di selezione del personale, o anche semplicemente di selezione di un interlocutore, non necessariamente sottoposto a valutazione ai fini di una possibile assunzione. Uno scenario tipico è mostrato in Figura 1. Il software rileva il movimento, oltre che consentire la registrazione, al fine poi di elaborare immagini e suoni per convertire i riscontri in sintetici indicatori di risultato. Il suddetto software può essere caratterizzato come un framework in grado di misurare la risonanza tra due o più soggetti al fine di misurare l’effettiva sinergia esistente. In particolare l’obiettivo è quello di inferire, a partire da dati legati ai parametri psico-attitudinali degli individui, il loro livello di sinergia. L’approccio utilizzato finora per derivare i parametri psico-attitudinali si sono rivelati spesse volte troppo invasivi, in quanto le tecnologie utilizzate costringevano l’utente a dover applicare sensori, e in parte a falsare il loro atteggiamento del valutando, in quanto consapevole di essere monitorato. Lo svilupparsi di nuove tecnologie, e la possibilità di tradurre in software quanto prima veniva invece declinato solo sotto forma di apparecchiature hardware, permette la ricerca della ottimizzazione dei dispositivi e un loro utilizzo più razionale. Allo scopo sono stati implementati degli algoritmi che, a partire da dati ottenuti attraverso degli opportuni sensori di tipo general purpose, quali rilevatori di movimento, apparati di registrazione della voce, videocamere, possano inferire informazioni sullo stato emotivo degli utenti monitorati. In tale scenario l’utilizzo di modelli psico-attitudinali, approcci probabilistici, in grado di permettere una rigorosa descrizione dei rapporti di sinergia, delle loro componenti e dei legami che intercorrono fra loro, permettono il raggiungimento degli obiettivi prefissi. Quindi il progetto percorre le seguenti direttrici principali:
Progettazione e implementazione di modelli psico-attitudinali in grado di misurare la sinergia fra utenti: in questo contesto sono stati indagati i modelli presenti in letteratura ed in seguito si sono identificati i parametri da quantificare;
A valle dell’identificazione dei parametri da quantificare sono stati identificati i sensori in grado di catturare i parametri e le tipologie di analisi da condurre sui dati da essi acquisiti. I sensori sono stati selezionati in modo da essere scarsamente invasivi e permettere all’utente di agire, nell’ambito dei contesti in cui avviene la misurazione, nel modo più naturale è possibile;
Progettazione ed implementazione di software in grado di inferire dai dati ottenuti dai sensori informazioni sulla sinergia degli utenti coinvolti. In particolare si provveduti a sviluppare strumenti che a partire dai dati siano in grado di inferire dei concetti relazionati allo stato emotivo dell’utente ed organizzare gli stessi in mappe concettuali in grado di permettere una loro manipolazione o sotto forma di formalismi probabilistici e sotto forma di dati grezzi a cui accedere con tecniche proprie del data-mining.
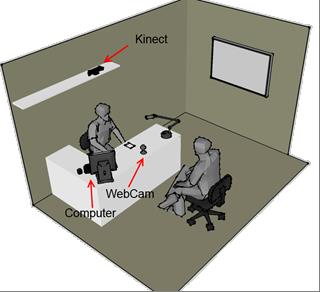
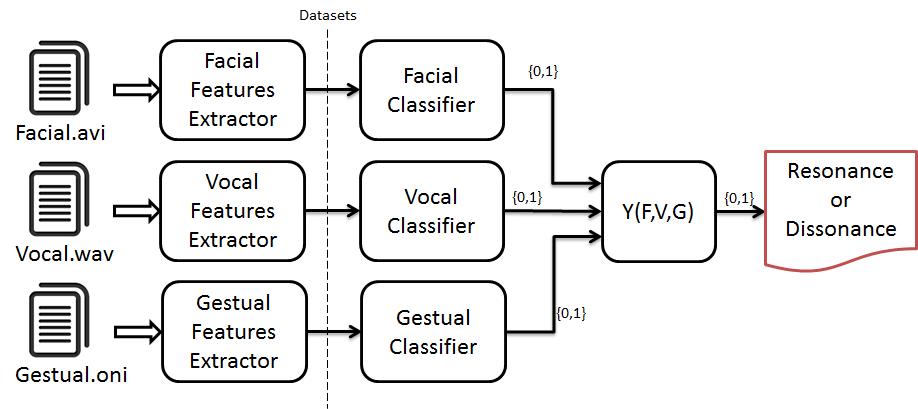
L’intero applicativo si basa sulla progettazione, l’implementazione ed infine l’integrazione di tre moduli indipendenti in grado di lavorare ciascuno sul proprio dominio di interesse: facciale, vocale e gestuale.
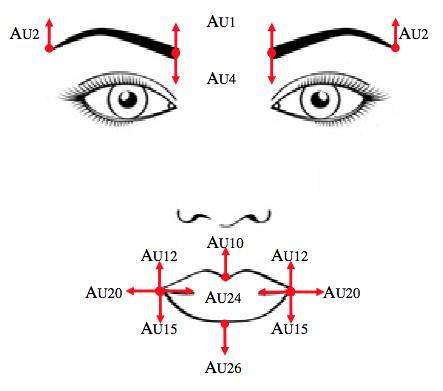
In particolare dal video dove è conservato il profilo facciale dell’utente vengono estratte le action units (AUs) nonché azioni facciali minimali le cui combinazioni creano le espressioni facciali. Un esempio di AUs sono l’innalzamento dell’angolo interno alla sopracciglia sinistra, rughe frontali, movimento delle labbra e così via, come mostrato in Figura 2. In Figura 3, è mostrato invece il workflow con cui vengono estratte le AUs.

Nel dominio del vocale, vengono estratte alcune features di tipo prosodiche e spettrali come ad esempio il Pitch, gli MFCC e l’armonicità. Tutte queste features avendo un’elevata variabilità frame per frame, sono stati considerati alcuni indicatori statistici come il valor medio, la deviazione standard, valore minimo, massimo e range.
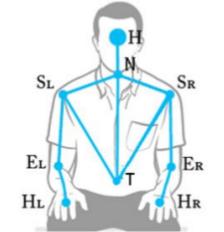
Per il dominio del gestuale, è stato sviluppato un sistema in grado di riconoscere 13 diverse azioni umane. Andando a processare la mappa di profondità si sono estratte diverse features che corrispondono a joints e distanze tra i vari joints. Un esempio di joints sono spalla sinistra, torso, mani, gomiti e così via, come mostrato in Figura 4.
In Figura 5 è mostrata l’architettura del sistema, illustrando come le varie componenti sono tutte separate fino alla loro fusione per la determinazione dello stato di risonanza e di dissonanza.
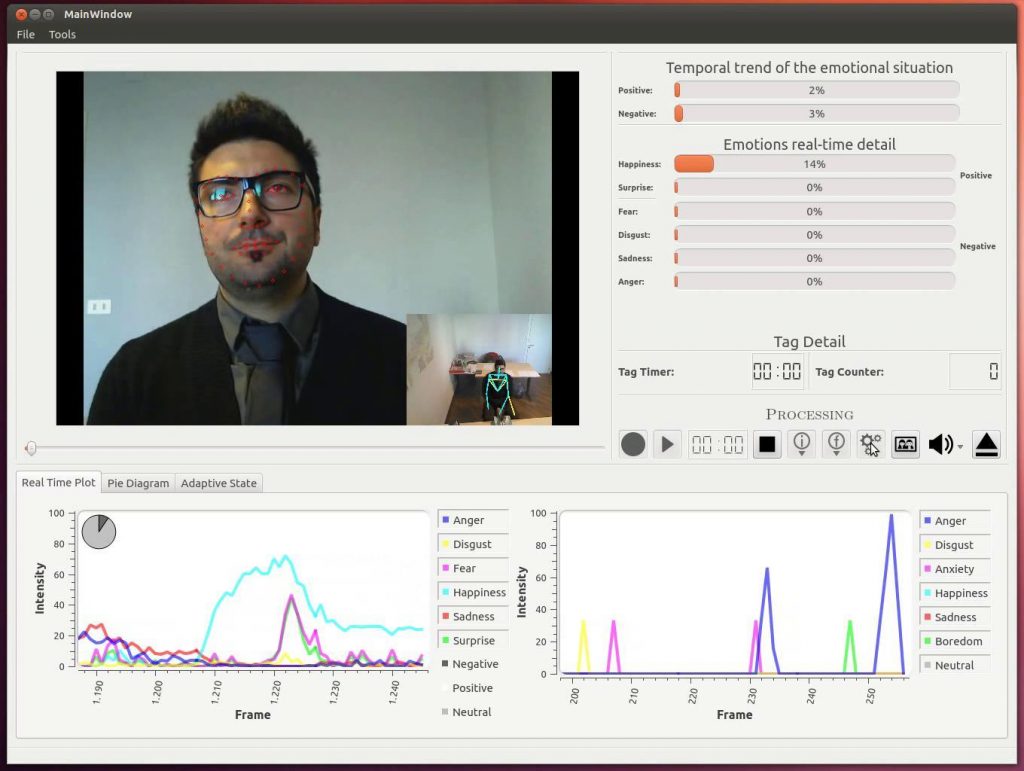
In Figura 6 è mostrata invece l’interfaccia grafica del prodotto software finale dove in alto a sinistra sono mostrate le elaborazioni facciali (descrittori sul viso) e gestuali (scheletro), in alto a destra vi è la valutazione delle emozioni in tempo reale con i relativi plot in basso.
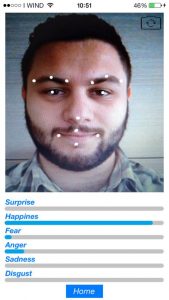
Il seguente applicativo cattura uno stream video dalla fotocamera del dispositivo o dalla galleria e dopo averlo processato mostra qual è lo stato emozionale del soggetto.
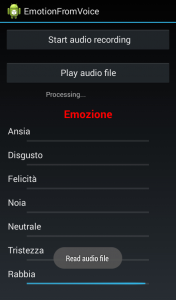
In un secondo step, viene catturato lo stream audio e successivamente processato mostrando lo stato emozionale del soggetto.
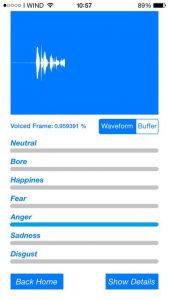
Nel seguente screenshot viene mostrato come è possibile verificare le corrispondenza tra le varie emozioni facciali e vocali ottenute dai due algoritmi.
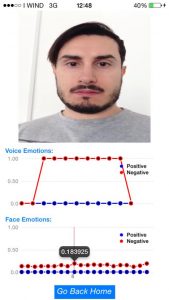
In ambiente Android, i requisiti funzionali per quanto concerne il riconoscimento delle emozioni vocali sono pressoché identici. Come mostra il seguente screenshot, dall’applicativo è possibile sia avviare una esecuzione real-time sia una esecuzione offline mediarte un file pre-registrato. Durante l’esecuzione verranno mostrat, mediante le progress bar, lo status emotivo.